分布式锁方案对比
分布式锁
当我们对一份数据进行修改的时候需要先读取,再修改,由于读取和修改不是原子操作,在并发的情况下,无法保证前后数据是一致的,在单点服务中我们可以使用本地锁来实现(比如:sync.Mutex),但是对于分布式系统服务,本地锁却无能为力。这时候就需要使用分布式锁来保证数据的一致性。
很多应用场景是需要系统保证幂等性的(如api服务或消息消费者),并发情况下或消息重复很容易造成系统重入,那么分布式锁是保障幂等的一个重要手段。还有一种场景就是商城做抢购活动、司机抢单等场景需要使用分布式锁来防止出现“超卖”现象。
实现方案
- 基于数据库的唯一索引
- 基于redis的setnx
- 基于zookeeper
基于数据库
基于唯一索引
基于数据库的实现方式的核心思想是:在数据库中创建一个表,表中包含方法名(或者变量等)等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁。
- 新建一张表
1 | DROP TABLE IF EXISTS `method_lock`; |
核心就是利用唯一索引的不可重复插入的特性,来控制锁的获取是释放。
- 想要执行某个方法,就使用这个方法名向表中插入数据:
1 | INSERT INTO method_lock (method_name, desc) VALUES ('methodName', '测试的methodName'); |
因为我们对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
- 成功插入则获取锁,执行完成后删除对应的行数据释放锁:
1 | delete from method_lock where method_name ='methodName'; |
乐观锁
乐观锁在操作数据时非常乐观,认为别人不会同时修改数据。因此乐观锁不会上锁,只是在执行更新的时候判断一下在此期间别人是否修改了数据:如果别人修改了数据则放弃操作,否则执行操作。
乐观锁大多数是基于数据版本(version)的记录机制实现的。何谓数据版本号?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表添加一个 “version”字段来实现读取出数据时,将此版本号一同读出,之后更新时,对此版本号加1。在更新过程中,会对版本号进行比较,如果是一致的,没有发生改变,则会成功执行本次操作;如果版本号不一致,则会更新失败。其实也可以为使用表的updated_at字段记录每次更新的时间戳,使用时间戳作为version字段。
乐观锁的优点比较明显,由于在检测数据冲突时并不依赖数据库本身的锁机制,不会影响请求的性能,当产生并发且并发量较小的时候只有少部分请求会失败。缺点是需要对表的设计增加额外的字段,增加了数据库的冗余,另外,当应用并发量高的时候,version值在频繁变化,则会导致大量请求失败,影响系统的可用性。数据库锁都是作用于同一行数据记录上,这就导致一个明显的缺点,在一些特殊场景,如大促、秒杀等活动开展的时候,大量的请求同时请求同一条记录的行锁(update),会对数据库产生很大的写压力。所以综合数据库乐观锁的优缺点,乐观锁比较适合并发量不高,并且写操作不频繁的场景。
悲观锁
悲观锁在操作数据时比较悲观,认为别人会同时修改数据。因此操作数据时直接把数据锁住,直到操作完成后才会释放锁;上锁期间其他人不能修改数据。
要使用悲观锁,我们必须关闭mysql数据库的自动提交属性,因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。set autocommit=0;
1 | //0.开始事务 |
在悲观锁中,每一次行数据的访问都是独占的,只有当正在访问该行数据的请求事务提交以后,其他请求才能依次访问该数据,否则将阻塞等待锁的获取。悲观锁可以严格保证数据访问的安全。但是缺点也明显,即每次请求都会额外产生加锁的开销且未获取到锁的请求将会阻塞等待锁的获取,在高并发环境下,容易造成大量请求阻塞,影响系统可用性。另外,悲观锁使用不当还可能产生死锁的情况。
缺陷
- 因为是基于数据库实现的,数据库的可用性和性能将直接影响分布式锁的可用性及性能,所以,数据库需要双机部署、数据同步、主备切换;
- 不具备可重入的特性,因为同一个线程在释放锁之前,行数据一直存在,无法再次成功插入数据,所以,需要在表中新增一列,用于记录当前获取到锁的机器和线程信息,在再次获取锁的时候,先查询表中机器和线程信息是否和当前机器和线程相同,若相同则直接获取锁;
- 没有锁失效机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁,所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据;
- 不具备阻塞锁特性,获取不到锁直接返回失败,所以需要优化获取逻辑,循环多次去获取。
- 在实施的过程中会遇到各种不同的问题,为了解决这些问题,实现方式将会越来越复杂;依赖数据库需要一定的资源开销,性能问题需要考虑。
基于redis的setnx
- 获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
1 | SETNX {ResourceURI} {UUID} |
- 释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
1 | // 比对 value 与 标识 |
缺陷
- setnx和expire操作的非原子特性会导致死锁问题。协程A执行setnx命令成功,结果运行协程A的服务发生异常重启,导致expire命令没有执行,那么就会由于锁没有设置超时时间形成死锁。
- A线程拿到锁超时释放,但是A依旧在执行自己的业务逻辑,此时B线程立刻获得锁,B也开始执行。这显然是不被允许的,一般会采取加大过期时间或者添加守护线程,go中也可以使用context设置过期时间。
- 上述方案无法达到不可重入,即在同一个协程中多次加锁。可以在本地维护一个map,map的key为锁标识,value为加锁次数。 每次加锁的时候加1, 重新设置过期时间,每次释放锁的时候减1,当计数小于或等于1的时候执行删除操作删除
基于zookeeper
利用zookeeper的临时有序节点和wathcer机制来实现分布式锁的功能。具体实现步骤如下:
- 创建一个目录lock
- 每个节点尝试获取锁时,首先在zookeeper的lock目录下创建一个znode节点,zookeeper的有序临时节点会自动根据创建先后顺序给节点编号。
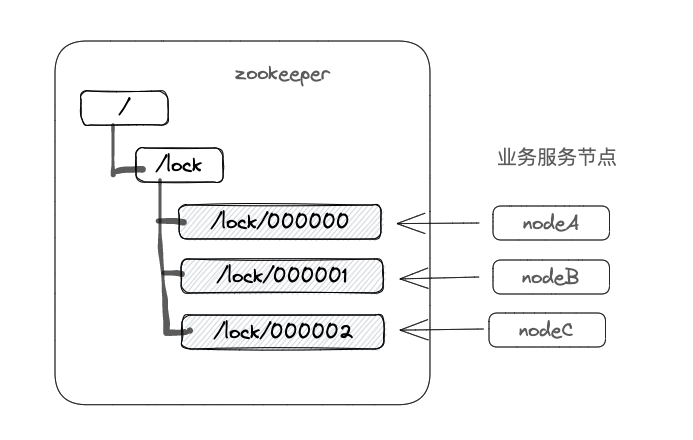
- 判断当前服务节点创建的znode节点是最小节点。
- 如果序列号是最小的,则成功获取到锁。执行完操作后,把创建的节点给删掉。
- 如果不是,则监听比自己要小 1 的节点变化。直到拿到自己是最小的节点时获得锁。
缺陷
虽然zookeeper具备高可用、可重入、阻塞锁特性,可解决失效死锁问题,但是因为需要频繁的创建和删除节点,性能上不如Redis方式。